專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2021-08-17 09:19:04 來源:動力節點 瀏覽2041次
隨著互聯網技術的發展與應用的普及,網絡作為信息的載體,已經成為社會大眾參與社會生活的一種重要信息渠道。由于互聯網是開放的,每個人都可以在網絡上發表信息,內容涉及各個方面。小到心情日志,大到國家大事。
互聯網已成為思想文化信息的集散地,并具有傳統媒體無法相比的優勢:便捷性,虛擬性,互動性,多元性。網絡新聞熱點通常形成迅速,多是人們對于日常生活中的各種問題發表的各種意見,評論,態度,情緒等,隨著事件的發展而變化,是反映社會熱點的重要載體之一。
相比較而言,編寫爬蟲程序獲取到的海量數據更為真實、全面,在信息繁榮的互聯網時代更為行之有效。因此編寫爬蟲程序成為大數據時代信息收集的必備技能。
大數據時代下,人類社會的數據正以前所未有的速度增長,傳統的獲取數據的方式如問卷調查、訪談法等,其樣本容量小、信度低、且受經費和地域范圍所限,因而收集的數據往往無法客觀反映研究對象,有著較大的局限性。
以不能滿足高質量研究的需求。正如Ivor的理論所揭示的,如果輸入的是無效信息,無論處理的程序如何精良,輸出的都是無用信息“Garbage In,Garbage Out”。可見,對比傳統的數據收集方法,立足于海量數據的研究有以下的優點:
(1)數據的真實性
數據的真實性,使用問卷調查法收集的數據,調查者難以了解被調查者是認真填寫還是敷衍了事。使得得到的數據真實性不可靠,而通過爬蟲技術能快速獲取真實、客觀的用戶信息,如在社交網絡上對一個公司的評價顯然要比問卷調查真實,淘寶、美團上消費者對賣家的評論就比較客觀的反應了商品的質量。
(2)樣本容量
人類當初發明計算機是因為在二戰時期工程師們已經無法計算導彈的飛行軌跡,龐大的計算量迫使了計算機的發明,可見計算機天生就是來處理大規模批量的數據,把人們從繁重的勞動中解放出來。在同樣的成本下,人工采集和計算機采集的數據量不是一個量級的,爬蟲可以對互聯網上的海量數據進行收集、分析,能更好的反應客觀事實,而數據越全面,分析研究的結果也就越真實。
網絡爬蟲(Web crawler),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本,我們瀏覽的網頁數以億計,它們在世界各地的服務器上存儲著。用戶點擊一個網頁的超鏈接以跳轉的方式來獲取另一個頁面的信息,而跳轉的頁面又有鏈接存在,網頁便由超鏈接組成一個巨大且錯綜復雜的網。而Web爬蟲(Crawler),也稱蜘蛛(Spider),則是穿梭在這巨大的互聯網中下載網頁解析內容的程序。它們被廣泛用于互聯網搜索引擎,可以自動采集所有其能夠訪問到的頁面內容,以獲取或更新這些網站的內容和檢索方式。
(1)爬蟲的應用
在商務智能上,企業使用爬蟲收集競爭對手的情報或在社交網絡、虛擬社區上爬取用戶對企業的評價從而在產品服務上做出改進等。在數據研究上,爬蟲能快速收集互聯網上的信息,為數據分析提供原始資料。
(2)爬蟲算法流程
從功能上來講,爬蟲一般分為數據采集,處理,儲存三個部分。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入隊列,直到滿足系統的一定停止條件。聚焦爬蟲的工作流程較為復雜,需要根據一定的網頁分析算法過濾與主題無關的鏈接,保留有用的鏈接將其放入等待抓取的URL隊列。然后,它將根據一定的搜索策略從隊列中選擇下一步要抓取的網頁URL,并重復上述過程,直到達到系統的某一條件時停止。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,并建立索引,以便之后的查詢和檢索;對于聚焦爬蟲來說,這一過程所得到的分析結果還可能對以后的抓取過程給出反饋和指導。
Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。其最初是為了頁面抓取 (更確切來說, 網絡抓取 )所設計的, 也可以應用在獲取API所返回的數據(例如 Amazon Associates Web Services ) 或者通用的網絡爬蟲。Scrapy用途廣泛,可以用于數據挖掘、監測和自動化測試。
(1)scrapy整體架構圖
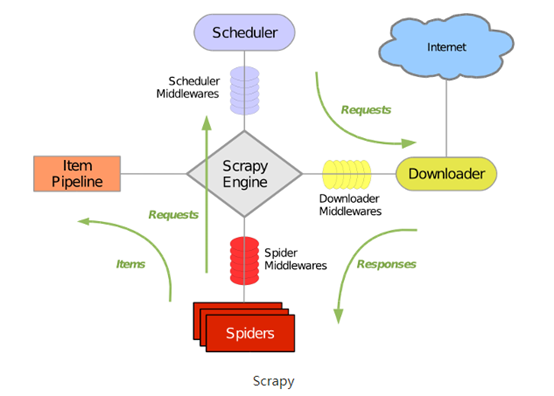
(2)Scrapy主要組件
1)引擎(Scrapy): 用來處理整個系統的數據流處理, 觸發事務(框架核心)。
2)調度器(Scheduler): 用來接受引擎發過來的請求, 壓入隊列中, 并在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是鏈接)的優先隊列, 由它來決定下一個要抓取的網址是什么, 同時去除重復的網址。
3)下載器(Downloader): 用于下載網頁內容, 并將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的異步模型上的)。
4)爬蟲(Spiders): 爬蟲是主要干活的, 用于從特定的網頁中提取自己需要的信息, 即所謂的實體(Item)。用戶也可以從中提取出鏈接,讓Scrapy繼續抓取下一個頁面。
5)項目管道(Pipeline): 負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的信息。當頁面被爬蟲解析后,將被發送到項目管道,并經過幾個特定的次序處理數據。
6)下載器中間件(Downloader Middlewares): 位于Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
7)爬蟲中間件(Spider Middlewares): 介于Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。
8)調度中間件(Scheduler Middewares): 介于Scrapy引擎和調度之間的中間件,從Scrapy引擎發送到調度的請求和響應。
scrapy是python界出名的一個爬蟲框架。Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
雖然scrapy能做的事情很多,但是要做到大規模的分布式應用則捉襟見肘。有能人改變了scrapy的隊列調度,將起始的網址從start_urls里分離出來,改為從redis讀取,多個客戶端可以同時讀取同一個redis,從而實現了分布式的爬蟲。
(1)scrapy-redis安裝
安裝:pip install scrapy-redis 官方站點:https://github.com/rolando/scrapy-redis
(2)scrapy-redis架構
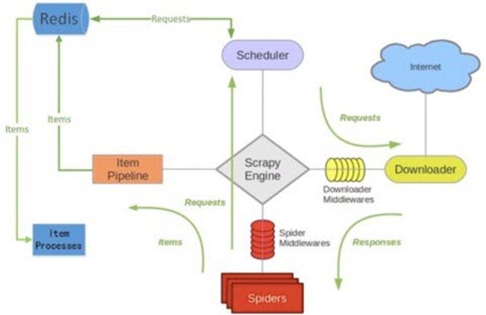
(3)scrapy-Redis組件詳解
如上圖所示,scrapy-redis在scrapy的架構上增加了redis,基于redis的特性拓展了如下四種組件:Scheduler,Duplication Filter,Item Pipeline,Base Spider
1)Scheduler: scrapy改造了python本來的collection.deque(雙向隊列)形成了自己的Scrapy
queue,但是Scrapy多個spider不能共享待爬取隊列Scrapy
queue,即Scrapy本身不支持爬蟲分布式,scrapy-redis 的解決是把這個Scrapy
queue換成redis數據庫(也是指redis隊列),從同一個redis-server存放要爬取的request,便能讓多個spider去同一個數據庫里讀取。Scrapy中跟“待爬隊列”直接相關的就是調度器Scheduler,它負責對新的request進行入列操作(加入Scrapy
queue),取出下一個要爬取的request(從Scrapy
queue中取出)等操作。它把待爬隊列按照優先級建立了一個字典結構,然后根據request中的優先級,來決定該入哪個隊列,出列時則按優先級較小的優先出列。為了管理這個比較高級的隊列字典,Scheduler需要提供一系列的方法。但是原來的Scheduler已經無法使用,所以使用Scrapy-redis的scheduler組件。
2)Duplication Filter
Scrapy中用集合實現這個request去重功能,Scrapy中把已經發送的request指紋放入到一個集合中,把下一個request的指紋拿到集合中比對,如果該指紋存在于集合中,說明這個request發送過了,如果沒有則繼續操作。
3)Item Pipeline:
引擎將(Spider返回的)爬取到的Item給Item Pipeline,scrapy-redis 的Item Pipeline將爬取到的
Item 存入redis的 items queue。修改過Item Pipeline可以很方便的根據 key 從 items queue
提取item,從而實現 items processes集群。
4)Base Spider
不在使用scrapy原有的Spider類,重寫的RedisSpider繼承了Spider和RedisMixin這兩個類,RedisMixin是用來從redis讀取url的類。
當我們生成一個Spider繼承RedisSpider時,調用setup_redis函數,這個函數會去連接redis數據庫,然后會設置signals(信號):一個是當spider空閑時候的signal,會調用spider_idle函數,這個函數調用schedule_next_request函數,保證spider是一直活著的狀態,并且拋出DontCloseSpider異常。一個是當抓到一個item時的signal,會調用item_scraped函數,這個函數會調用schedule_next_request函數,獲取下一個request。
5)總結
總結一下scrapy-redis的總體思路:這套組件通過重寫scheduler和spider類,實現了調度、spider啟動和redis的交互;
實現新的dupefilter和queue類,達到了判重和調度容器和redis的交互,因為每個主機上的爬蟲進程都訪問同一個redis數據庫,所以調度和判重都統一進行統一管理,達到了分布式爬蟲的目的;當spider被初始化時,同時會初始化一個對應的scheduler對象,這個調度器對象通過讀取settings,配置好自己的調度容器queue和判重工具dupefilter;
每當一個spider產出一個request的時候,scrapy引擎會把這個reuqest遞交給這個spider對應的scheduler對象進行調度,scheduler對象通過訪問redis對request進行判重,如果不重復就把他添加進redis中的調度器隊列里。當調度條件滿足時,scheduler對象就從redis的調度器隊列中取出一個request發送給spider,讓他爬取;
當spider爬取的所有暫時可用url之后,scheduler發現這個spider對應的redis的調度器隊列空了,于是觸發信號spider_idle,spider收到這個信號之后,直接連接redis讀取strart_url池,拿去新的一批url入口,然后再次重復上邊的工作。
以上就是動力節點小編介紹的"scrapy-redis分布式爬蟲框架詳解",希望對大家有幫助,想了解更多可查看Java分布式應用教程。動力節點在線學習教程,針對沒有任何Java基礎的讀者學習,讓你從入門到精通,主要介紹了一些Java基礎的核心知識,讓同學們更好更方便的學習和了解Java編程,感興趣的同學可以關注一下。
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習




官方微信

官方抖音














 京公網安備 11030102010736號
京公網安備 11030102010736號