數據:是數據庫中存儲的基本對象,在計算機中的概念是廣義的,描述事物的符號記錄稱為數據,比如你手機里的音樂、文檔和圖形都是數據。
數據庫:數據庫(Database,DB),簡單的來講就是存放數據的倉庫,嚴格來講,是長期存儲在計算機內,有組織、可共享的大量數據集合。
數據庫管理系統:數據庫管理系統(Database Management System,DBMS)是位于用戶與操作系統之間的一層數據管理軟件,用來定義數據,管理數據。
數據庫系統:數據庫系統由數據、數據庫、數據庫管理系統(及其開發應用工具)、應用程序和數據庫管理員(DBA)組成的存儲、管理、處理和維護數據的系統,人們通常把它簡稱為數據庫。
物理模型是對數據最底層的抽象,它描述數據在系統內部的表示方式和存取方法,或在磁盤或磁帶上的存儲方式和存儲方法,是面向計算機系統的。
概念模型實際上是現實世界到機器世界的一個中間層次,用于信息世界的建模,是現實世界到信息世界的第一層抽象。
邏輯模型是按計算機系統的觀點對數據建模,主要用于數據庫管理系統的實現。常用的邏輯模型主要有層次模型、網狀模型、關系模型、面向對象數據模型、對象關系數據模型和半結構化數據模型。
關系型數據庫是依據關系模型來創建的數據庫,所謂關系模型就是“一對一”、“一對多”、“對多對”等。常見的關系型數據庫有Oracle、MySQL、SQL Server等。
非關系型數據庫主要基于“非關系型模型”,其中非關系型模型有:列模型、鍵值對模型、文檔類模型。比如redis屬于鍵值對模型。
優點
易于維護:都是使用表結構,格式一致。
使用方便:SQL語言通用,可用于復雜查詢。
復雜操作:支持SQL,可用于一個表以及多個表之間非常復雜的查詢。
缺點
讀寫性能比較差,尤其是海量數據的高效率讀寫。
固定的表結構,靈活度稍欠。
高并發讀寫需求,傳統關系型數據庫來說,硬盤I/O是一個很大的瓶頸。
優點
格式靈活:存儲數據的格式可以是key,value形式、文檔形式、圖片形式等,使用靈活,應用場景廣泛,而關系型數據庫則只支持基礎類型。
速度快:nosql可使用硬盤或者隨機存儲器作為載體,關系型數據庫只能使用硬盤。
高拓展性
成本低:nosql數據庫部署簡單,基本都是開源軟件。
缺點
不提供sql支持,學習和使用成本較高。
無事務處理。
數據結構相對復雜,復雜查詢方面稍欠。
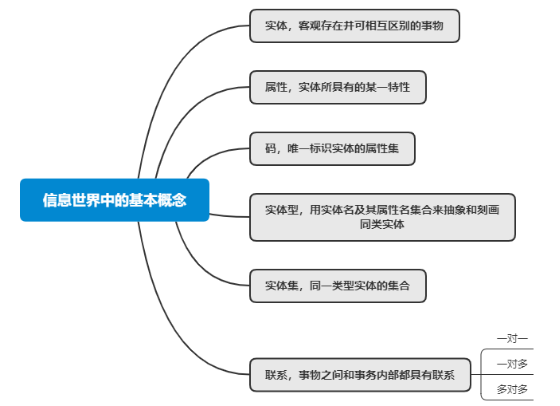
E-R模型是使用E-R圖來描述現實世界的概念模型,是描述概念模型的有力工具。
● 1對1(1:1),比如一個客戶只有一個會員卡,一個會員卡屬于一個客戶
● 1對多(1:n),比如一個系有多個班級,一個班級屬于一個系
● 多對多(n:m) ,比如一個學生可以選修多門課程,一門課程可以支持多名同學參加
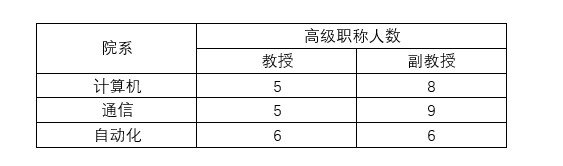
第一范式:每個表都應該有主鍵,并且每個字段要求原子性不可再分。
如以下表存在可再分項(高級職稱),所以不滿足第一范式。
第二范式:建立在第一范式基礎之上,所有非主鍵字段必須完全依賴主鍵,不能產生部分依賴。
舉例如關系模型(職工號,姓名,職稱,項目號,項目名稱)中,職工號->姓名,職工號->職稱,而項目號->項目名稱。顯然依賴關系不滿足第二范式,常用的解決辦法是差分表格,比如拆分為職工信息表和項目信息表。
第三范式:建立在第二范式基礎之上,所有非主鍵字段必須直接依賴主鍵,不能產生傳遞依賴。
比如Student表(學號,姓名,年齡,性別,所在院校,院校地址,院校電話)這樣一個表結構,就存在上述關系。 學號--> 所在院校 --> (院校地址,院校電話)。我們應該拆開來,如下:(學號,姓名,年齡,性別,所在院校)--(所在院校,院校地址,院校電話)
設計范式的最終目的是:減少數據的冗余。但在實際的開發中,我們以滿足客戶的需求為目的,有的時候也會拿冗余來換取速度。(建議把這句話說上,體現工作經驗)
1)MySQL是一個輕量級的關系型數據庫(開源),Oracle是一個重量級的關系型數據庫(收費)
2) MySQL支持自增主鍵(auto increment),而Oracle支持序列
3)MySQL占內存小,Oracle占內存大
4)MySQL字符串用雙引號,Oracle用單引號
5)MySQL分頁用limit,Oacle使用rownum表名位置,而且只能用小于
6)MySQL用0、1判斷真假,Oracle用true、false
7)MySQL的事務級別是repeatable read,oracle的事務隔離性是read committed
● 左連接(左外連接):以左表作為基準進行查詢,左表數據會全部顯示出來,右表如果和左表數據不匹配則顯示為null。
● 右連接(右外連接):以右表作為基準進行查詢,右表數據會全部顯示出來,左表如果和右表的數據不匹配則顯示為null。
● 全連接:先以左表進行左外連接,再以右表進行右外連接。
● 內連接:顯示表之間有連接匹配的所有行。
● 笛卡爾積也叫交叉連接
數據定義:Create Table,Alter Table,Drop/Truncate Table, Create/Drop Index
數據操縱:Select ,Insert,Update,Delete
數據控制:Grant,Revoke
NOT NULL: 用于控制字段的內容一定不能為空(NULL)。
UNIQUE: 控件字段內容不能重復,一個表允許有多個 Unique 約束。
PRIMARY KEY: 也是用于控件字段內容不能重復,但它在一個表只允許出現一個。
FOREIGN KEY: 用于預防破壞表之間連接的動作,也能防止非法數據插入外鍵列,因為它必須是它指向的那個表中的值之一。
CHECK: 用于控制字段的值范圍。
事務是邏輯上的一組操作,要么都執行,要么都不執行。事務最經典的例子就是轉賬了。假如小明要給小紅轉賬1000元,這個轉賬會涉及到兩個關鍵操作就是:將小明的余額減少1000元,將小紅的余額增加1000元。萬一在這兩個操作之間突然出現錯誤比如銀行系統崩潰,導致小明余額減少而小紅的余額沒有增加,這樣就不對了。事務就是保證這兩個關鍵操作要么都成功,要么都要失敗。
數據庫事務transanction正確執行的四個基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔離性(Isolation)、持久性(Durability)。
● 原子性:事務是最小的執行單位,不允許分割。整個事務中的所有操作,要么全部完成,要么全部不完成,不可能停滯在中間某個環節。
● 一致性:在事務開始之前和事務結束以后,數據庫的完整性沒有被破壞。
● 隔離性:并發訪問數據庫時,一個用戶的事務不被其他事務所干擾,各并發事務之間數據庫是獨立的;
● 持久性:在事務完成以后,該事務對數據庫中數據的改變是持久的。即使數據庫發生故障也不應該對其有任何影響。
數據庫的隔離級別越高,并發性就越差,性能就越低。
oracle的隔離級別默認是READ COMMITED
mysql的隔離級別默認是REPEATABLE READ,mysql下的事務默認是自動提交的。
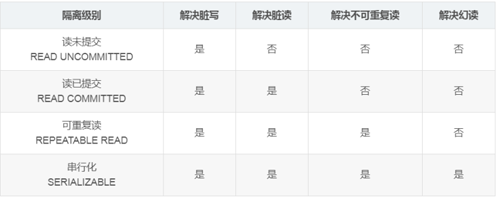
讀未提交:事務A在事務B未提交前讀取數據,如果事務B撤銷了修改,那么A會讀取到臟數據。因為事務B提交前的數據在緩存中
讀已提交:事務A分別在事務B提交前和提交后讀取數據,出現不可重復讀。因為事務B提交前的數據在緩存,事務B提交后的數據在硬盤,而事務A一直讀取的都是硬盤的數據從而導致不能夠重復讀的問題。
可重復讀:事務A在事務B添加一條數據提交后,事務A讀取記錄數的時候不一致出現幻讀。不可重復讀的重點在于Update和Delete,而幻讀在于Insert。
在典型的應用程序中,如果多個事務并發運行可能會導致以下的問題。

在不同的隔離級別下,V值分別如下:
| 讀未提交 | 讀已提交 | 可重復讀 | 串行化 | |
|---|---|---|---|---|
| V1 | 2 | 1 | 1 | 1 |
| V2 | 2 | 2 | 1 | 1 |
| V3 | 2 | 2 | 2 | 2 |
與標準的SQL隔離級別不同的是,InnoDB在可重復讀級別下,利用Next-Key Lock解決了幻讀問題,能夠完全保證事務的隔離性,達到了串行化級別。
索引最大的好處是提高查詢速度,
缺點是更新數據時效率低,因為要同時更新索引
對數據進行頻繁查詢進建立索引,如果要頻繁更改數據不建議使用索引。
聚簇索引:將數據存儲與索引放到了一塊,找到索引也就找到了數據。
非聚簇索引:將數據存儲于索引分開結構,索引結構的葉子節點指向了數據的對應行,MyISAM通過key_buffer把索引先緩存到內存中,當需要訪問數據時(通過索引訪問數據),在內存中直接搜索索引,然后通過索引找到磁盤相應數據,這也就是為什么索引不在key buffer命中時,速度慢的原因。
1.聚集索引決定了數據庫的物理存儲結構,而主鍵只是確定表格邏輯組織方式。這兩者不可混淆!
2.在InnoDB下主鍵索引是聚集索引,在MyISAM下主鍵索引是非聚集索引。
存儲過程是用戶定義的一系列sql語句的集合,涉及特定表或其它對象的任務,用戶可以調用存儲過程,而函數通常是數據庫已定義的方法,它接收參數并返回某種類型的值并且不涉及特定用戶表。
存儲過程,就是一些編譯好了的SQL語句,這些SQL語句代碼像一個方法一樣實現一些功能(對單表或多表的增刪改查),然后給這些代碼塊取一個名字,在用到這個功能的時候調用即可。
優點:存儲過程是一個預編譯的代碼塊,執行效率比較高;存儲過程在服務器端運行,減少客戶端的壓力;允許模塊化程序設計,只需要創建一次過程,以后在程序中就可以調用該過程任意次,類似方法的復用;一個存儲過程替代大量T_SQL語句 ,可以降低網絡通信量,提高通信速率;可以一定程度上確保數據安全。
缺點:調試麻煩、可移植性不靈活、重新編譯問題.
1)觸發器,指一段代碼,當觸發某個事件時,自動執行這些代碼。
2)使用場景:可以通過數據庫中的相關表實現級聯更改;實時監控某張表中的某個字段的更改而需要做出相應的處理。
視圖是一種虛擬的表,具有和物理表相同的功能。可以對視圖進行增,改,查,操作,視圖通常是有一個表或者多個表的行或列的子集。對視圖的修改不影響基本表。它使得我們獲取數據更容易,相比多表查詢。
游標:是對查詢出來的結果集作為一個單元來有效的處理。游標可以定在該單元中的特定行,從結果集的當前行檢索一行或多行。可以對結果集當前行做修改。一般不使用游標,但是需要逐條處理數據的時候,游標顯得十分重要。
1)使用視圖可以簡化復雜的sql操作,隱藏具體的細節,保護數據;
2)視圖不能被索引,也不能有關聯的觸發器或默認值,如果視圖本身內有order by則對視圖再次order by將被覆蓋。對于某些視圖,例如,未使用聯結子查詢分組聚集函數Distinct Union等,是可以對其更新的,對視圖的更新將對基表進行更新;但是視圖主要用于簡化檢索,保護數據,并不用于更新,而且大部分視圖都不可以更新。
數據庫連接是一種關鍵的有限的昂貴的資源,對數據庫連接的管理能顯著影響到整個應用程序的伸縮性和健壯性,影響到程序 的性能指標。數據庫連接池正是針對這個問題提出來的。
數據庫連接池負責分配、管理和釋放數據庫連接,它允許應用程序重復使用一個現有的數據庫連接,而不是重新建立一個;釋放空閑時間超過最大空閑時間的數據庫連接來避免因為沒有釋放數據庫連接而引起的數據庫連接遺漏。這項技術能明顯提高對數據庫操作的性能。
數據庫連接池在初始化時將創建一定數量的數據庫連接放到連接池中,這些數據庫連接的數量是由最小數據庫連接數來設定的。無論這些數據庫連接是否被使用,連接池都將一直保證至少擁有這么多的連接數量。連接池的最大數據庫連接數量限定了 這個連接池能占有的最大連接數,當應用程序向連接池請求的連接數超過最大連接數量時,這些請求將被加入到等待隊列中。

官方微信

官方抖音










 京公網安備 11030102010736號
京公網安備 11030102010736號