CAP原理指的是,在分布式系統中這三個要素最多只能同時實現兩點,不可能三者兼顧。因此在進行分布式架構設計時,必須做出取舍。而對于分布式數據系統,分區容忍性是基本要求,否則就失去了價值。因此設計分布式數據系統,就是在一致性和可用性之間取一個平衡。對于大多數Web應用,其實并不需要強一致性,因此犧牲一致性而換取高可用性,是目前多數分布式數據庫產品的方向。
一致性(Consistency):數據在多個副本之間是否能夠保持一致的特性。(當一個系統在一致狀態下更新后,應保持系統中所有數據仍處于一致的狀態)。
可用性(Availability):系統提供的服務必須一直處于可用狀態,對每一個操作的請求必須在有限時間內返回結果。
分區容錯性(Tolerance of network Partition):分布式系統在遇到網絡分區故障時,仍然需要保證對外提供一致性和可用性的服務,除非整個網絡都發生故障。
例如,服務器中原本存儲的value=0,當客戶端A修改value=1時,為了保證數據的一致性,要寫到3個服務器中,當服務器C故障時,數據無法寫入服務器C,則導致了此時服務器A、B和C的value是不一致的。這時候要保證分區容錯性,即當服務器C故障時,仍然能保持良好的一致性和可用性服務,則Consistency和Availability不能同時滿足。為什么呢? 如果滿足了一致性,則客戶端A的寫操作value=1不能成功,這時服務器中所有value=0。如果滿足可用性,即所有客戶端都可以提交操作并得到返回的結果,則此時允許客戶端A寫入服務器A和B,客戶端C將得到未修改之前的value=0結果。
1)Basically Available(基本可用)分布式系統在出現不可預知故障的時候,允許損失部分可用性
2)Soft state(軟狀態)軟狀態也稱為弱狀態,和硬狀態相對,是指允許系統中的數據存在中間狀態,并認為該中間狀態的存在不會影響系統的整體可用性,即允許系統在不同節點的數據副本之間進行數據同步的過程存在延時。
2)Eventually consistent(最終一致性)最終一致性強調的是系統中所有的數據副本,在經過一段時間的同步后,最終能夠達到一個一致的狀態。因此,最終一致性的本質是需要系統保證最終數據能夠達到一致,而不需要實時保證系統數據的強一致性。
ACID 是傳統數據庫常用的設計理念,追求強一致性模型。BASE 支持的是大型分布式系統,提出通過犧牲強一致性獲得高可用性。 ACID 和 BASE 代表了兩種截然相反的設計哲學,在分布式系統設計的場景中,系統組件對一致性要求是不同的,因此 ACID 和 BASE 又會結合使用。
接口的冪等性實際上就是接口可重復調用,在調用方多次調用的情況下,接口最終得到的結果是一致的。有些接口可以天然的實現冪等性,比如查詢接口,對于查詢來說,你查詢一次和兩次,對于系統來說,沒有任何影響,查出的結果也是一樣。除了查詢功能具有天然的冪等性之外,增加、更新、刪除都要保證冪等性。
1)全局唯一ID:全局唯一ID就是根據業務的操作和內容生成一個全局ID,在執行操作前先根據這個全局唯一ID是否存在,來判斷這個操作是否已經執行。如果不存在則把全局ID,存儲到存儲系統中,比如數據庫、redis等。如果存在則表示該方法已經執行。 從工程的角度來說,使用全局ID做冪等可以作為一個業務的基礎的微服務存在,在很多的微服務中都會用到這樣的服務,在每個微服務中都完成這樣的功能,會存在工作量重復。另外打造一個高可靠的冪等服務還需要考慮很多問題,比如一臺機器雖然把全局ID先寫入了存儲,但是在寫入之后掛了,這就需要引入全局ID的超時機制。 使用全局唯一ID是一個通用方案,可以支持插入、更新、刪除業務操作。但是這個方案看起來很美但是實現起來比較麻煩,下面的方案適用于特定的場景,但是實現起來比較簡單。
2)去重表:這種方法適用于在業務中有唯一標的插入場景中,比如在以上的支付場景中,如果一個訂單只會支付一次,所以訂單ID可以作為唯一標識。這時,我們就可以建一張去重表,并且把唯一標識作為唯一索引,在我們實現時,把創建支付單據和寫入去去重表,放在一個事務中,如果重復創建,數據庫會拋出唯一約束異常,操作就會回滾。
3)插入或更新:這種方法插入并且有唯一索引的情況,比如我們要關聯商品品類,其中商品的ID和品類的ID可以構成唯一索引,并且在數據表中也增加了唯一索引。這時就可以使用InsertOrUpdate操作。在mysql數據庫中如下:
insert into goods_category (goods_id,category_id,create_time,update_time)?
? ? ? ?values(#{goodsId},#{categoryId},now(),now())?
? ? ? ?on DUPLICATE KEY UPDATE
? ? ? ?update_time=now()
4)多版本控制:這種方法適合在更新的場景中,比如我們要更新商品的名字,這時我們就可以在更新的接口中增加一個版本號,來做冪等
boolean updateGoodsName(int id,String newName,int version);
在實現時可以如下
update goods set name=#{newName},version=#{version} where id=#{id} and version<${version}
5)狀態機控制:這種方法適合在有狀態機流轉的情況下,比如就會訂單的創建和付款,訂單的付款肯定是在之前,這時我們可以通過在設計狀態字段時,使用int類型,并且通過值類型的大小來做冪等。比如訂單的創建為0,付款成功為100,付款失敗為99 。
在做狀態機更新時,我們就這可以這樣控制
update `order` set status=#{status} where id=#{id} and status<#{status}
分布式事務是指事務的參與者、支持事務的服務器、資源服務器以及事務管理器分別位于不同的分布式系統的不同節點之上。一個大的操作由 N 多的小的操作共同完成。而這些小的操作又分布在不同的服務上。針對于這些操作,要么全部成功執行,要么全部不執行。
1.UUID:時間戳+時鐘序列(計數器)+唯一的IEEE機器識別碼(比如網卡的MAC地址) 。
缺點:對數據庫不友好,因為隨機不連續。
2.數據庫自增:對于數據庫集群模型,要設置不同的數據庫起始值不同,但是步長(自增幾)相同。
3.Leaf-segment:(美團大眾點評的)采用每次獲取一個ID區間的方式。比如一次和數據庫的交互,就請求到100個id,數據來了直接用。避免每次添加數據都請求一個id,增加了數據庫的壓力。 也是對數據庫自增策略的一個優化。
4.雪花算法:其核心思想是:41位時間戳+10位機器id+12位序列號+符號位(0)。結果是一個長度為64bit的long型的ID。
優點:12位序列號是說每個節點在每毫秒可以產生4096 個ID,并且是遞增的。 這樣適合于Mysql的聚集索引,索引的連續性也好。
缺點:依賴于時間戳,時間戳是根據機器的時間得到的。比如linux中,如果人為的進行時鐘回撥,就可能造成id重復。
● 使用jwt
● 使用cookie (有安全風險)
● 服務器之間進行session同步:保證每個服務器都有session信息,消耗比較大。
● ip綁定策略:比如使用Ngnix進行源地址哈希法的負載均衡,讓每一個ip固定訪問一個服務器, 但是這種就失去分布式的作用。
● 使用redis存儲:是業界最廣泛的。 可實現不同服務,不同平臺(網頁/app),甚至不同語言的session共享。
1)基于數據庫做分布式鎖--樂觀鎖(基于版本號)和悲觀鎖(基于排它鎖)
2)基于redis做分布式鎖:setnx(key,當前時間+過期時間)和Redlock機制
3)基于zookeeper做分布式鎖:臨時有序節點來實現的分布式鎖,Curator
4)基于 Consul 做分布式鎖
基于數據庫(MySQL)的分布式鎖方案,一般分為3類:基于表記錄、樂觀鎖和悲觀鎖。
該方法是最簡單的,就是直接創建一張鎖表。當我們想要獲得鎖的時候,就可以在該鎖表中增加一條記錄,想要釋放鎖的時候就刪除鎖表的這條記錄。
總結:
1.這種鎖沒有失效時間,一旦釋放鎖操作失敗就會導致鎖記錄一直在數據庫中,其它線程無法獲得鎖。這個缺陷也很好解決,比如可以做一個定時任務去定時清理。
2.這種鎖的可靠性依賴于數據庫。建議設置備庫,避免單點,進一步提高可靠性。
3.這種鎖是非阻塞的。因為插入數據失敗之后會直接報錯,想要獲得鎖就需要再次操作。如果需要阻塞式的,可以弄個for循環、while循環之類的,直至INSERT成功再返回。
4.這種鎖是非可重入的。因為數據庫中鎖表的一份記錄就是一把鎖,想要實現可重入鎖,可以在數據庫中添加一些字段,比如獲得鎖的主機信息、線程信息等,那么在再次獲得鎖的時候可以先查詢數據,如果當前的主機信息和線程信息等能被查到的話,可以直接把鎖分配給它。
樂觀鎖大多數是基于數據版本(version)的記錄機制實現的。通過對數據庫表添加一個 “version”字段來實現的。讀數據時會將此版本號一同讀出,之后更新數據時會對此版本號加1。在更新過程中,會對版本號進行比較,如果是一致的,沒有發生改變,則會成功執行更新操作;如果版本號不一致,則執行不會更新。
當然借助更新時間戳(updated_at)也可以實現樂觀鎖,和采用version字段的方式相似:更新操作執行前先記錄當前的更新時間,在提交更新時,檢測當前更新時間是否與更新開始時獲取的更新時間戳相等。
樂觀鎖的優點:由于在檢測數據沖突時并不依賴數據庫本身的鎖機制,不會影響請求的性能,當產生并發且并發量較小的時候只有少部分請求會失敗。
樂觀鎖的缺點:需要對表的設計增加額外的字段,增加了數據庫的冗余。另外,當應用并發量高的時候,version值在頻繁變化,會對數據庫產生很大的寫壓力。并且也會導致大量請求失敗,影響系統的可用性。所以數據庫樂觀鎖比較適合并發量不高,并且寫操作不頻繁的場景。
悲觀鎖是數據庫中自帶的。在查詢語句后面增加FOR UPDATE,數據庫會在查詢過程中給數據庫表增加悲觀鎖,也稱排他鎖。悲觀鎖就會比較悲觀,總是假設最壞的情況,它認為數據的更新在大多數情況下是會產生沖突的。
在使用悲觀鎖的同時,我們需要注意一下鎖的級別。MySQL InnoDB在加鎖的時候,只有明確地指定主鍵(或索引)的才會執行行鎖 (只鎖住被選取的數據),否則將會執行表鎖(將整個數據表單給鎖住)。
在使用悲觀鎖時,我們必須關閉MySQL數據庫的自動提交屬性(參考下面的示例),因為MySQL默認使用autocommit(自動提交)模式。這樣在使用FOR UPDATE獲得鎖之后可以執行相應的業務邏輯,執行完之后再使用COMMIT來釋放鎖。
悲觀鎖優點:可以嚴格保證數據訪問的安全。
悲觀鎖缺點:即每次請求都會額外產生加鎖的開銷且未獲取到鎖的請求將會阻塞等待鎖的獲取,在高并發環境下,容易造成大量請求阻塞,影響系統可用性。另外,悲觀鎖使用不當還可能產生死鎖的情況。
ZooKeeper是一個分布式的,開放源碼的分布式應用程序協調服務,Zookeeper在本質上就像一個文件管理系統。其用類似文件路徑的方式管理來監聽多個節點(Znode),同時判斷當前每個節點上機器的狀態(是否宕機、是否斷開連接等),從而達到分布式協同的操作。
ZooKeeper 可以根據有序節點+watch實現,實現思路,如:為每個線程生成一個有序的臨時節點,為確保有序性,在排序一次全部節點,獲取全部節點,每個線程判斷自己是否最小,如果是的話,獲得鎖,執行操作,操作完刪除自身節點。如果不是第一個的節點則監聽它的前一個節點,當它的前一個節點被刪除時,則它會獲得鎖,以此類推。
1. Redis分布式鎖需要不斷去嘗試獲取鎖,比較消耗性能。而ZooKeeper分布式鎖,獲取不到鎖會注冊個監聽器,不需要不斷主動嘗試獲取鎖因此性能開銷較小;
2. 如果是Redis獲取鎖的那個客戶端bug了或者掛了,那么只能等待超時時間之后才能釋放鎖;而ZooKeeper的話,因為創建的是臨時znode,只要客戶端掛了,znode就沒了,此時就自動釋放鎖;
SETNX 是SET IF NOT EXISTS的簡寫.日常命令格式是SETNX key value,如果 key不存在,則SETNX成功返回1,如果這個key已經存在了,則返回0。
偽代碼實現如下:假設某電商網站的某商品做秒殺活動,key可以設置為key_resource_id,value設置任意值
if(jedis.setnx(key_resource_id,lock_value) == 1){ //加鎖 ? ??
? ? expire(key_resource_id,100);//設置過期時間 ? ??
? ? try { ? ? ? ??
? ? ? ? do something ?//業務請求 ? ??
? ? }catch(){ ??
? ? }finally { ? ? ? ?
? ? ? ? jedis.del(key_resource_id); //釋放鎖 ? ??
? ? }
}
缺點:setnx和expire兩個命令分開了,不是原子操作。如果執行完setnx加鎖,正要執行expire設置過期時間時,進程crash或者要重啟維護了,那么這個鎖就永遠釋放不了,別的線程永遠獲取不到鎖啦。
為了解決發生異常鎖得不到釋放的場景,可以把過期時間放到setnx的value值里面。如果加鎖失敗,再拿出value值校驗一下即可。加鎖代碼如下:
long expires = System.currentTimeMillis() + expireTime; //系統時間+設置的過期時間
String expiresStr = String.valueOf(expires);
// 如果當前鎖不存在,返回加鎖成功
if (jedis.setnx(key_resource_id, expiresStr) == 1) {
return true;
}
// 如果鎖已經存在,獲取鎖的過期時間
String currentValueStr = jedis.get(key_resource_id);
// 如果獲取到的過期時間,小于系統當前時間,表示已經過期
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 鎖已過期,獲取上一個鎖的過期時間,并設置現在鎖的過期時間(不了解redis的getSet命令的小伙伴,可以去官網看下哈)
String oldValueStr = jedis.getSet(key_resource_id, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考慮多線程并發的情況,只有一個線程的設置值和當前值相同,它才可以加鎖
return true;
}
}
//其他情況,均返回加鎖失敗
return false;
}
缺點:
1.過期時間是客戶端自己生成的(System.currentTimeMillis()是當前系統的時間),必須要求分布式環境下,每個客戶端的時間必須同步。
2.如果鎖過期的時候,并發多個客戶端同時請求過來,都執行jedis.getSet(),最終只能有一個客戶端加鎖成功,因此某個客戶端加的鎖可能被別的客戶端所覆蓋。
3.該鎖沒有保存持有者的唯一標識,可能被別的客戶端釋放/解鎖。
SET key value[EX seconds][PX milliseconds][NX|XX]
● EX seconds :設定key的過期時間,時間單位是秒。
● PX milliseconds: 設定key的過期時間,單位為毫秒。
● NX :表示key不存在的時候,才能set成功,也即保證只有第一個客戶端請求才能獲得鎖,而其他客戶端請求只能等其釋放鎖,才能獲取。
● XX: 僅當key存在時設置值;
if(jedis.set(key_resource_id,lock_value,"NX","EX",100s)==1){//加鎖
try{
dosomething
//業務處理
}catch(){
}finally {
jedis.del(key_resource_id); //釋放鎖
}
}
缺點:
問題一:鎖過期釋放了,業務還沒執行完。假設線程a獲取鎖成功,一直在執行臨界區的代碼。但是100s過去后,它還沒執行完。但是,這時候鎖已經過期了,此時線程b又請求過來。顯然線程b就可以獲得鎖成功,也開始執行臨界區的代碼。那么問題就來了,臨界區的業務代碼都不是嚴格串行執行的啦。
問題二:鎖被別的線程誤刪。假設線程a執行完后,去釋放鎖。但是它不知道當前的鎖可能是線程b持有的(線程a去釋放鎖時,有可能過期時間已經到了,此時線程b進來占有了鎖)。那線程a就把線程b的鎖釋放掉了,但是線程b臨界區業務代碼可能都還沒執行完呢。
既然鎖可能被別的線程誤刪,那我們給value值設置一個標記當前線程唯一的隨機數,在刪除的時候,校驗一下:
if(jedis.set(key_resource_id,uni_request_id,"NX","EX",100s)==1){
//加鎖
try {
do something //業務處理
}catch(){
}finally {
//判斷是不是當前線程加的鎖,是才釋放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //釋放鎖
}
}
}
方案四中還是可能存在鎖過期釋放,業務沒執行完的問題。開源框架Redisson解決了這個問題。先來看下Redisson底層原理圖:
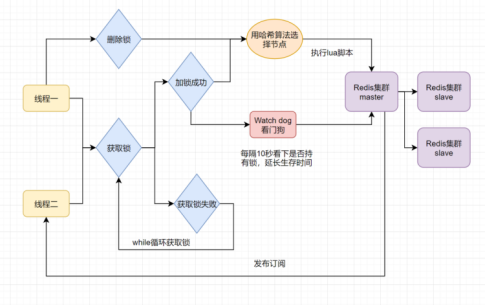
只要線程一加鎖成功,就會啟動一個watch dog看門狗,它是一個后臺線程,會每隔10秒檢查一下,如果線程1還持有鎖,那么就會不斷的延長鎖key的生存時間。因此Redisson解決了鎖過期釋放,業務沒執行完問題。
前面五種方案都是基于單機版的,其實Redis一般都是集群部署的。為了解決這個問題,Redis作者 antirez提出一種高級的分布式鎖算法:Redlock。
XA協議是一個基于數據庫的分布式事務協議,其分為兩部分:事務管理器和本地資源管理器。事務管理器作為一個全局的調度者,負責對各個本地資源管理器統一號令提交或者回滾。二階提交協議(2PC)和三階提交協議(3PC)就是根據此協議衍生出來而來。主流的諸如Oracle、MySQL等數據庫均已實現了XA接口。 XA接口是雙向的系統接口,在事務管理器(Transaction Manager)以及一個或多個資源管理器(Resource Manager)之間形成通信橋梁。也就是說,在基于XA的一個事務中,我們可以針對多個資源進行事務管理,例如一個系統訪問多個數據庫,或即訪問數據庫、又訪問像消息中間件這樣的資源。這樣我們就能夠實現在多個數據庫和消息中間件直接實現全部提交、或全部取消的事務。XA規范不是java的規范,而是一種通用的規范。
兩段提交顧名思義就是要進行兩個階段的提交:
第一階段,準備階段(投票階段);
第二階段,提交階段(執行階段);
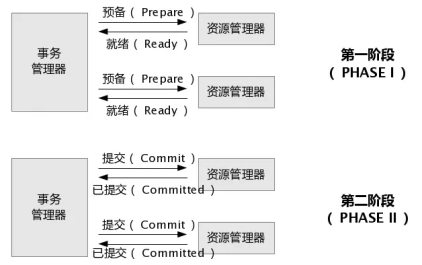
二階段提交看似能夠提供原子性的操作,但它存在著嚴重的缺陷:
1)網絡抖動導致的數據不一致:第二階段中協調者向參與者發送commit命令之后,一旦此時發生網絡抖動,導致一部分參與者接收到了commit請求并執行,可其他未接到commit請求的參與者無法執行事務提交。進而導致整個分布式系統出現了數據不一致。
2)超時導致的同步阻塞問題:2PC中的所有的參與者節點都為事務阻塞型,當某一個參與者節點出現通信超時,其余參與者都會被動阻塞占用資源不能釋放。 3)單點故障的風險:由于嚴重的依賴協調者,一旦協調者發生故障,而此時參與者還都處于鎖定資源的狀態,無法完成事務commit操作。雖然協調者出現故障后,會重新選舉一個協調者,可無法解決因前一個協調者宕機導致的參與者處于阻塞狀態的問題。
三段提交(3PC)是對兩段提交(2PC)的一種升級優化,3PC在2PC的第一階段和第二階段中插入一個準備階段。保證了在最后提交階段之前,各參與者節點的狀態都一致。同時在協調者和參與者中都引入超時機制,當參與者各種原因未收到協調者的commit請求后,會對本地事務進行commit,不會一直阻塞等待,解決了2PC的單點故障問題,但3PC還是沒能從根本上解決數據一致性的問題。
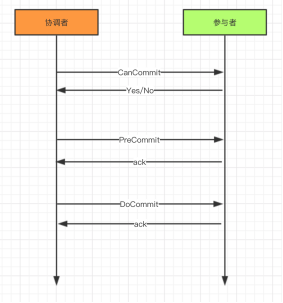
3PC的三個階段分別是CanCommit、PreCommit、DoCommit: CanCommit:協調者向所有參與者發送CanCommit命令,詢問是否可以執行事務提交操作。如果全部響應YES則進入下一個階段。 PreCommit:協調者向所有參與者發送PreCommit命令,詢問是否可以進行事務的預提交操作,參與者接收到PreCommit請求后,如參與者成功的執行了事務操作,則返回Yes響應,進入最終commit階段。一旦參與者中有向協調者發送了No響應,或因網絡造成超時,協調者沒有接到參與者的響應,協調者向所有參與者發送abort請求,參與者接受abort命令執行事務的中斷。 DoCommit:在前兩個階段中所有參與者的響應反饋均是YES后,協調者向參與者發送DoCommit命令正式提交事務,如協調者沒有接收到參與者發送的ACK響應,會向所有參與者發送abort請求命令,執行事務的中斷。
TCC(Try-Confirm-Cancel)又被稱補償事務,TCC與2PC的思想很相似,事務處理流程也很相似,但2PC是應用于在DB層面,TCC則可以理解為在應用層面的2PC,是需要我們編寫業務邏輯來實現。 TCC它的核心思想是:"針對每個操作都要注冊一個與其對應的確認(Try)和補償(Cancel)"。 還拿下單扣庫存解釋下它的三個操作:
Try階段:下單時通過Try操作去扣除庫存預留資源。
Confirm階段:確認執行業務操作,在只預留的資源基礎上,發起購買請求。
Cancel階段:只要涉及到的相關業務中,有一個業務方預留資源未成功,則取消所有業務資源的預留請求。
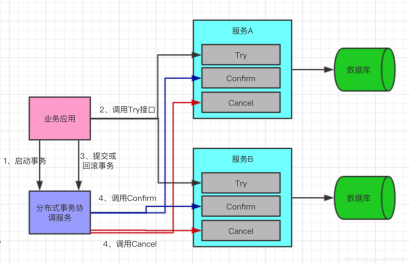
1)解決了協調者單點,由主業務方發起并完成這個業務活動。業務活動管理器也變成多點,引入集群。
2)同步阻塞:引入超時,超時后進行補償,并且不會鎖定整個資源,將資源轉換為業務邏輯形式,粒度變小。
3)數據一致性,有了補償機制之后,由業務活動管理器控制一致性。
總之,TCC 就是通過代碼人為實現了兩階段提交,不同的業務場景所寫的代碼都不一樣,并且很大程度的增加了業務代碼的復雜度。因此,這種模式并不能很好地被復用。
應用侵入性強:TCC由于基于在業務層面,至使每個操作都需要有try、confirm、cancel三個接口。
開發難度大:代碼開發量很大,要保證數據一致性confirm和cancel接口還必須實現冪等性。

官方微信

官方抖音










 京公網安備 11030102010736號
京公網安備 11030102010736號