在MySQL中,事務(wù)是在存儲引擎層實現(xiàn)的。對于InnoDB而言:
● 原子性代表著可回滾,這一特性主要有undo log實現(xiàn);
● 隔離性需要在效率上作出平衡,在不同的隔離級別下主要由MVCC和鎖實現(xiàn);
● 持久性主要由redo log和double write實現(xiàn),redo log是一種Write Ahead Log(WAL)策略,用于對數(shù)據(jù)頁進行重做;double write則用于防止臟頁刷盤時部分寫失效導(dǎo)致的數(shù)據(jù)丟失。
MVCC(Multiversion concurrency control,多版本并發(fā)控制協(xié)議),是一種提高系統(tǒng)并發(fā)的技術(shù),在很多情況下避免了加鎖操作。MVCC通過undo log來構(gòu)建數(shù)據(jù)的歷史版本,通過視圖來定義數(shù)據(jù)版本的可見性。并由此構(gòu)建數(shù)據(jù)庫在某一個時間點的全庫快照(一致性視圖),來實現(xiàn)一致性非鎖定讀,保障事務(wù)的隔離性和一致性。
事務(wù)是用戶定義的一個數(shù)據(jù)庫操作序列,這些操作要么全做要么全不做,是一個不可分割的工作單位,事務(wù)回滾是指將該事務(wù)已經(jīng)完成的對數(shù)據(jù)庫的更新操作撤銷。
要同時修改數(shù)據(jù)庫中兩個不同表時,如果它們不是一個事務(wù)的話,當?shù)谝粋€表修改完,可能第二個表修改過程中出現(xiàn)了異常而沒能修改,此時就只有第二個表依舊是未修改之前的狀態(tài),而第一個表已經(jīng)被修改完畢。而當你把它們設(shè)定為一個事務(wù)的時候,當?shù)谝粋€表修改完,第二表修改出現(xiàn)異常而沒能修改,第一個表和第二個表都要回到未修改的狀態(tài),這就是所謂的事務(wù)回滾。
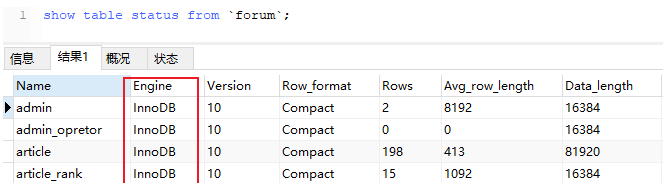
show table status from `forum`; --forum是指定數(shù)據(jù)庫名
show engines;
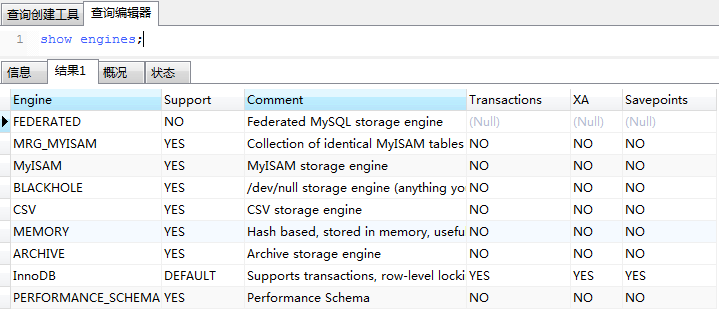 Transaction:是否支持事務(wù)
Transaction:是否支持事務(wù)
XA:是否通過XA協(xié)議實現(xiàn)分布式事務(wù)(分為本地資源管理器,事務(wù)管理器)。
Savepoint:是否用來實現(xiàn)子事務(wù)(嵌套事務(wù))。創(chuàng)建了一個Savepoints之后,事務(wù)就可以回滾到這個點,不會影響到創(chuàng)建Savepoints之前的操作。
MyISAM(3 個文件)特點:只讀之類的數(shù)據(jù)分析的項目
1. 支持表級別的鎖(插入和更新會鎖表)。不支持事務(wù)
2. 擁有較高的插入(insert)和查詢(select)速度
3. MyISAM 用一個變量保存了整個表的行數(shù),執(zhí)行select count(*) from table語句時只需要讀出該變量即可,速度很快;
InnoDB(2 個文件)特點:經(jīng)常更新的表,存在并發(fā)讀寫或者有事務(wù)處理的業(yè)務(wù)系統(tǒng)。
1. 支持事務(wù),支持外鍵,因此數(shù)據(jù)的完整性、一致性更高
2. 支持行級別的鎖和表級別的鎖
3. 支持讀寫并發(fā),寫不阻塞讀(MVCC)
4. 特殊的索引存放方式,可以減少IO,提升查詢效率
MyISAM 和InnoDB 是我們用得最多的兩個存儲引擎,在 MySQL 5.5 版本之前,默認的存儲引擎是MyISAM。5.5版本之后默認的存儲引擎改成了InnoDB,為什么要改呢?最主要的原因還是InnoDB 支持事務(wù),支持外鍵,支持行級別的鎖,對于業(yè)務(wù)一致性要求高的場景來說更適合。
InnoDB:適用對數(shù)據(jù)一致性要求比較高,需要事務(wù)支持
MyISAM:適用數(shù)據(jù)查詢多更新少,對查詢性能要求比較高。
Memory:適用一個用于查詢的臨時表。
索引其實是一種數(shù)據(jù)結(jié)構(gòu),能夠幫助我們快速的檢索數(shù)據(jù)庫中的數(shù)據(jù)。
首先數(shù)據(jù)是以文件的形式存放在磁盤上面的,每一行數(shù)據(jù)都有它的磁盤地址。如果沒有索引的話,要從500萬行數(shù)據(jù)里面檢索一條數(shù)據(jù),只能依次遍歷這張表的全部數(shù)據(jù),直到找到這條數(shù)據(jù)。但是有了索引之后,只需要在索引里面去檢索這條數(shù)據(jù)就行了,因為它是一種特殊的專門用來快速檢索的數(shù)據(jù)結(jié)構(gòu),我們找到數(shù)據(jù)存放的磁盤地址以后,就可以拿到數(shù)據(jù)了。就像我們從一本 500 頁的書里面去找特定的一小節(jié)的內(nèi)容,肯定不可能從第一頁開始翻。那么這本書有專門的目錄,它可能只有幾頁的內(nèi)容,它是按頁碼來組織的,可以根據(jù)拼音或者偏旁部首來查找,只要確定內(nèi)容對應(yīng)的頁碼,就能很快地找到我們想要的內(nèi)容。
優(yōu)點
● 提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫IO成本。
● 通過索引對數(shù)據(jù)進行排序,降低數(shù)據(jù)的排序成本,降低CPU的消耗。
缺點
● 建立索引需要占用物理空間
● 會降低表的增刪改的效率,因為每次對表記錄進行增刪改,需要進行動態(tài)維護索引,導(dǎo)致增刪改時間變長
需要建索引的情況
1. 主鍵自動創(chuàng)建唯一索引
2. 較頻繁的作為查詢條件的字段
3. 查詢中排序的字段,查詢中統(tǒng)計或者分組的字段
不需要建索引的情況
1. 表記錄太少的字段
2. 經(jīng)常增刪改的字段
3. 唯一性太差的字段,不適合單獨創(chuàng)建索引。比如性別,民族,政治面貌
索引的數(shù)據(jù)結(jié)構(gòu)是B+樹(加強版多路平衡查找樹),原理:如下圖,是一顆B+樹,淺藍色的塊我們稱之為一個磁盤塊,可以看到每個磁盤塊包含幾個數(shù)據(jù)項(深藍色所示)和指針(黃色所示),如磁盤塊1包含數(shù)據(jù)項17和35,包含指針P1、P2、P3,P1表示小于17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大于35的磁盤塊。真實的數(shù)據(jù)存在于葉子節(jié)點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非葉子節(jié)點只不存儲真實的數(shù)據(jù),只存儲指引搜索方向的數(shù)據(jù)項,如17、35并不真實存在于數(shù)據(jù)表中。
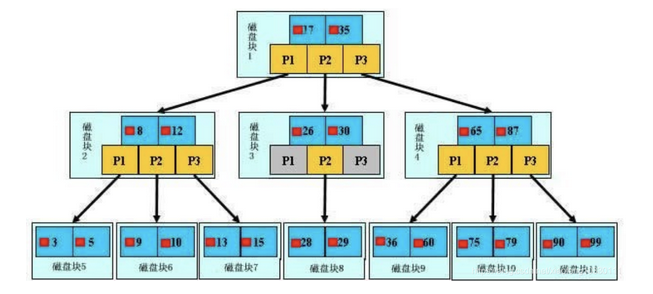
查找過程:如圖所示,如果要查找數(shù)據(jù)項29,那么首先會把磁盤塊1由磁盤加載到內(nèi)存,此時發(fā)生一次IO,在內(nèi)存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,內(nèi)存時間因為非常短(相比磁盤的IO)可以忽略不計,通過磁盤塊1的P2指針的磁盤地址把磁盤塊3由磁盤加載到內(nèi)存,發(fā)生第二次IO,29在26和30之間,鎖定磁盤塊3的P2指針,通過指針加載磁盤塊8到內(nèi)存,發(fā)生第三次IO,同時內(nèi)存中做二分查找找到29,結(jié)束查詢,總計三次IO。真實的情況是,3層的b+樹可以表示上百萬的數(shù)據(jù),如果上百萬的數(shù)據(jù)查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數(shù)據(jù)項都要發(fā)生一次IO,那么總共需要百萬次的IO,顯然成本非常非常高。
優(yōu)點:保證等值和范圍查詢的快速查找。
先來說說二叉查找樹(BST Binary Search Tree),二叉查找樹在數(shù)組和鏈表的基礎(chǔ)上整合出來的一個新的數(shù)據(jù)結(jié)構(gòu)。
1. 二叉查找樹(BST Binary Search Tree)
二叉查找樹的特點是左子樹所有的節(jié)點都小于父節(jié)點,右子樹所有的節(jié)點都大于父節(jié)點。投影到平面以后,就是一個有序的線性表。
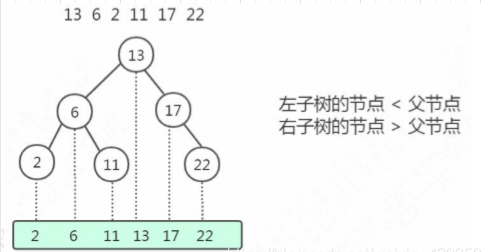
比如我們插入的數(shù)據(jù)是有序的[2、6、11、13、17、22] ,那么這個時候我們的二叉查找樹變成了什么樣了呢?如下圖:
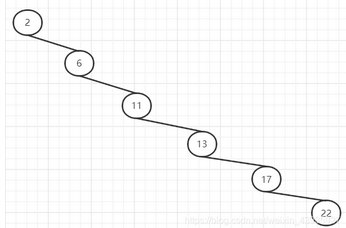
很明顯,樹變成鏈表了,因為左右子樹深度差太大,這棵樹的左子樹根本沒有節(jié)點——也就是它不夠平衡。
優(yōu)點:能夠?qū)崿F(xiàn)快速查找和插入。
缺點:樹的深度會影響查找效率。
1. 平衡二叉樹(Balanced binary search trees)
平衡二叉樹又稱紅黑樹,除了具備二叉樹的特點,最主要的特征是左右子樹深度差絕對值不能超過1。例如我們按順序插入1、2、3、4、5、6,就會變成如下圖:
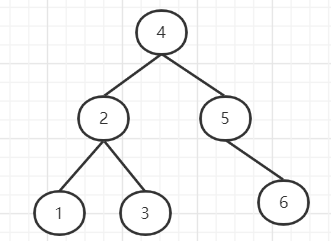
優(yōu)點:在插入刪除數(shù)據(jù)時通過左旋/右旋操作保持二叉樹的平衡,不會出現(xiàn)左子樹很高、右子樹很矮的情況。
缺點:
● 時間復(fù)雜度和樹高相關(guān)。樹有多高就需要檢索多少次,每個節(jié)點的讀取,都對應(yīng)一次磁盤 IO 操作。樹的高度就等于每次查詢數(shù)據(jù)時磁盤 IO 操作的次數(shù)。在表數(shù)據(jù)量大時,查詢性能就會很差。
● 平衡二叉樹不支持快速的范圍查找,范圍查找時需要從根節(jié)點多次遍歷,查詢效率不高。
1)單列索引:一個索引只包含單個列,但一個表中可以有多個單列索引。
主鍵索引:主鍵是一種唯一性索引,但它必須指定為PRIMARY KEY,每個表只能有一個主鍵。
唯一索引:索引列的所有值都只能出現(xiàn)一次,即必須唯一,值可以為空。
CREATE UNIQUE INDEX account_UNIQUE_Index ON `award`(`account`);
普通索引:基本的索可以為空,沒有唯一性的限制。
CREATE INDEX account_Index ON `award`(`account`);
2)復(fù)合索引:
符合索引遵循索引最左匹配原則,舉例:創(chuàng)建一個(a,b)的聯(lián)合索引,那么它的索引樹就是下圖的樣子。
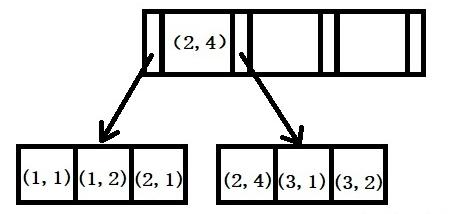
可以看到a的值是有順序的,1,1,2,2,3,3,而b的值是沒有順序的1,2,1,4,1,2。但是我們又可發(fā)現(xiàn)a在等值的情況下,b值又是按順序排列的,但是這種順序是相對的。這是因為MySQL創(chuàng)建聯(lián)合索引的規(guī)則是首先會對聯(lián)合索引的最左邊第一個字段排序,在第一個字段的排序基礎(chǔ)上,然后在對第二個字段進行排序。
復(fù)合索引是包含兩個或兩個以上字段的索引。
create index a_b_c_index on table1(a,b,c)
創(chuàng)建的聯(lián)合索引a_b_c_index,實際上相當于建立了三個索引(a)、(a_b)、(a_b_c)。
注意:
● 查詢必須從索引的最左邊的列開始,否則無法使用索引。比如直接使用b或著c,此時索引會失效。
● 查詢不能跳過某一個索引。比如使用了a索引,但是跳過了b,使用了c,此時只有a索引有用,而c索引失效。
● 查詢中如果使用了范圍查詢,那么其右側(cè)的索引列會失效。比如a=1 and b>2 and c=3.此時b使用了范圍查詢,>、like等。c索引列不會起作用。
3) 全文索引
全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT類型字段上使用全文索引,介紹了要求,說說什么是全文索引,就是在一堆文字中,通過其中的某個關(guān)鍵字等,就能找到該字段所屬的記錄行,比如有"我愛學(xué)編程尤其是java ..." 通過java,可能就可以找到該條記錄。這里說的是可能,因為全文索引的使用涉及了很多細節(jié),我們只需要知道這個大概意思。一般開發(fā)中,不貴用到全文索引,因為其占用很大的物理空間和降低了記錄修改性,故較為少用。
在查詢sql前面加一個explain,如explain select ..........
 我們只需要注意一個最重要的type 的信息很明顯的提現(xiàn)是否用到索引,type結(jié)果值從好到壞依次是:
我們只需要注意一個最重要的type 的信息很明顯的提現(xiàn)是否用到索引,type結(jié)果值從好到壞依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般來說,得保證查詢至少達到range級別,最好能達到ref,否則就可能會出現(xiàn)性能問題。其中possible_keys:sql所用到的索引
聚簇索引就是將數(shù)據(jù)(一行一行的數(shù)據(jù))跟索引結(jié)構(gòu)放到一塊,innodb存儲引擎使用的就是聚簇索引;聚集索引中表記錄的排列順序和索引的排列順序一致,所以查詢效率快,只要找到第一個索引值記錄,其余就連續(xù)性的記錄在物理也一樣連續(xù)存放。聚集索引對應(yīng)的缺點就是修改慢,因為為了保證表中記錄的物理和索引順序一致,在記錄插入的時候,會對數(shù)據(jù)頁重新排序。
而非聚集索引:制定了表中記錄的邏輯順序,但是記錄的物理和索引不一定一致,兩種索引都采用B+樹結(jié)構(gòu),非聚集索引的葉子層并不和實際數(shù)據(jù)頁相重疊,而采用葉子層包含一個指向表中的記錄在數(shù)據(jù)頁中的指針方式。非聚集索引層次多,不會造成數(shù)據(jù)重排。
1.由于行數(shù)據(jù)和聚簇索引的葉子節(jié)點存儲在一起,同一頁(16k)中會有多條行數(shù)據(jù),訪問同一數(shù)據(jù)頁不同行記錄時,已經(jīng)把頁加載到了Buffer中(讀取數(shù)據(jù)是按頁讀取的),再次訪問時,會在內(nèi)存中完成訪問,不必訪問磁盤。這樣主鍵和行數(shù)據(jù)是一起被載入內(nèi)存的,找到葉子節(jié)點就可以立刻將行數(shù)據(jù)返回了,如果按照主鍵Id來組織數(shù)據(jù),獲得數(shù)據(jù)更快。
2.輔助索引的葉子節(jié)點,存儲主鍵值,而不是數(shù)據(jù)的存放地址。好處是當行數(shù)據(jù)放生變化時,索引樹的節(jié)點也需要分裂變化;或者是我們需要查找的數(shù)據(jù),在上一次IO讀寫的緩存中沒有,需要發(fā)生一次新的IO操作時,可以避免對輔助索引的維護工作,只需要維護聚簇索引樹就好了。另一個好處是,因為輔助索引存放的是主鍵值,減少了輔助索引占用的存儲空間大小。
3.因為MyISAM的主索引并非聚簇索引,那么他的數(shù)據(jù)的物理地址必然是凌亂的,拿到這些物理地址,按照合適的算法進行I/O讀取,于是開始不停的尋道不停的旋轉(zhuǎn)。聚簇索引則只需一次I/O。不過,如果涉及到大數(shù)據(jù)量的排序、全表掃描、count之類的操作的話,還是MyISAM占優(yōu)勢些,因為索引所占空間小,這些操作是需要在內(nèi)存中完成的。
主鍵最好不要使用uuid,因為uuid的值太過離散,不適合排序且可能出現(xiàn)新增加記錄的uuid,會插入在索引樹中間的位置,出現(xiàn)頁分裂(比如之前的索引已經(jīng)緊湊的排列在一起了,你此時需要在已經(jīng)緊湊排列好的數(shù)據(jù)中插入數(shù)據(jù)就會導(dǎo)致前面已經(jīng)排好序的索引出現(xiàn)松動和重構(gòu)排序,但是使用自增id就不會出現(xiàn)這種情況了),導(dǎo)致索引樹調(diào)整復(fù)雜度變大,消耗更多的時間和資源。但是使用自增主鍵就可以避免出現(xiàn)頁分裂,因為自增主鍵后面的主鍵值是要比前面的大, 那后來的數(shù)據(jù)直接放在后面就行;
聚簇索引的數(shù)據(jù)的物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那么對應(yīng)的數(shù)據(jù)一定也是相鄰地存放在磁盤上的。如果主鍵不是自增id,它會不斷地調(diào)整數(shù)據(jù)的物理地址、分頁,當然也有其他一些措施來減少這些操作,但卻無法徹底避免。但如果是自增的id,它只需要一 頁一頁地寫,索引結(jié)構(gòu)相對緊湊,磁盤碎片少,效率也高。
如果一個查詢是先走輔助索引(聚簇索引外的索引都叫輔助索引)的,那么通過這個輔助索引(innodb中的輔助索引的data存儲的是主鍵)沒有獲取到我們想要的全部數(shù)據(jù),那么MySQL就會拿著輔助索引查詢出來的主鍵去聚簇索引中進行查詢,這個過程就是叫回表;
所謂的索引覆蓋是索引高效找到行的一個方法,當能通過檢索索引就可以讀取想要的數(shù)據(jù),那就不需要再到數(shù)據(jù)表中讀取行了。如果一個索引包含了(或覆蓋了)滿足查詢語句中字段與條件的數(shù)據(jù)就叫做覆蓋索引。
============
注意:id 字段是聚簇索引,age 字段是普通索引(二級索引)
select id,age from user where age = 30;
上面的這個sql是不用回表查詢的,因為在非聚簇索引的葉子節(jié)點上已經(jīng)有id和age的值。所以根本不需要拿著id的值再去聚簇索引定位行記錄數(shù)據(jù)了。也就是在這一顆索引樹上就可以完成對數(shù)據(jù)的檢索,這樣就實現(xiàn)了覆蓋索引。
select id,age,name from user where age = 30;
而上面的這個sql不能實現(xiàn)索引覆蓋了,因為name的值在age索引樹上是沒有的,還是需要拿著id的值再去聚簇索引定位行記錄數(shù)據(jù)。但是如果我們對age和name做一個組合索引idx_age_name(age,name),那就又可以實現(xiàn)索引覆蓋了。
1)like查詢以%開頭,因為會導(dǎo)致查詢出來的結(jié)果無序;如:應(yīng)盡量避免使用模糊查詢, like "xxxx%" 是可以用到索引的,like "%xxxx" 則不行(like "%xxx%" 同理)。否則將導(dǎo)致引擎將放棄使用索引而進行全表掃描。
2)類型轉(zhuǎn)換,列計算也會可能會讓索引失效,因為結(jié)果可能是無序的,也可能是有序的;如:應(yīng)盡量避免在where子句中的“=”左邊進行函數(shù)、算術(shù)運算或其他表達式運算,否則將導(dǎo)致引擎放棄使用索引而進行全表掃描。如:select id from t where num/2=100應(yīng)改為:select id from t where num=100*2
3)在一些查詢的語句中,MySQL認為走全表掃描也會導(dǎo)致索引失效;如:應(yīng)盡量避免使用is null 和is not null 、in和not in,否則將導(dǎo)致引擎將放棄使用索引而進行全表掃描。
對于連續(xù)的數(shù)值用between就不要用in,如:select id from t where num in(1,2,3) 替換成:select id from t where num between 1 and 3
用exists代替in,如:select num from a where num in(select num from b) 替換成:select num from a where exists(select 1 from b where num=a.num)
4)如果條件中有or并且or連接的字段中有列沒有索引,那么即使其中有條件帶索引也不會使用索引 (這是因為MySQL判斷即便你開始走了索引查詢,但是它發(fā)現(xiàn)查詢中有or ,也就是說or 后面的還是需要走全表掃描(因為or會導(dǎo)致后面的數(shù)據(jù)是無序的),所以MySQL還不如一開始就直接走全表掃描,這也是為什么盡量少用or的原因)要想使用or,又想讓索引生效,只能將or條件中的每個列都加上索引,當檢索條件有or但是所有的條件都有索引時,索引不失效,可以走【兩個索引】,這叫索引合并(取二者的并集);
5)復(fù)合索引不滿足最左原則就不能使用全部索引,如:注意最佳左前綴法則,比如建立了一個聯(lián)合索引(a,b,c),那么其實我們可利用的索引就有(a), (a,b), (a,b,c)。
索引的b+樹結(jié)構(gòu),為什么使用b+樹說一下,然后再說一下聚簇索引,回表和索引覆蓋;
然后再談一下索引失效;
如sum. avg, count, max, min等
1、LOCATE(substr , str ):返回子串 substr 在字符串 str 中第一次出現(xiàn)的位置,如果字符substr在字符串str中不存在,則返回0;
2、POSITION(substr IN str ):返回子串 substr 在字符串 str 中第一次出現(xiàn)的位置,如果字符substr在字符串str中不存在,與LOCATE函數(shù)作用相同;
3、LEFT(str, length):從左邊開始截取str,length是截取的長度;
4、RIGHT(str, length):從右邊開始截取str,length是截取的長度;
5、SUBSTRING_INDEX(str ,substr ,n):返回字符substr在str中第n次出現(xiàn)位置之前的字符串;
6、SUBSTRING(str ,n ,m):返回字符串str從第n個字符截取到第m個字符;
7、REPLACE(str, n, m):將字符串str中的n字符替換成m字符;
8、LENGTH(str):計算字符串str的長度。
1)從含義上講,count(1) 與 count(*) 都表示對全部數(shù)據(jù)行的查詢。count(*) 包括了所有的列,相當于行數(shù),在統(tǒng)計結(jié)果的時候,不會忽略列值為NULL ;count(1) 用1代表代碼行,在統(tǒng)計結(jié)果的時候不會忽略列值為NULL 。
2)執(zhí)行效率上:
count(*)對行的數(shù)目進行計算,包含NULL,count(1)這個用法和count(*)的結(jié)果是一樣的。如果表沒有主鍵,那么count(1)比count(*)快。表有主鍵,count(*)會自動優(yōu)化到主鍵列上。如果表只有一個字段,count(*)最快。
count(1)跟count(主鍵)一樣,只掃描主鍵。count(*)跟count(非主鍵)一樣,掃描整個表。明顯前者更快一些。
count(1)和count(*)基本沒有差別,但在優(yōu)化的時候盡量使用count(1)。
1) DATE_FORMAT(time, ‘%Y-%m-%d’) 或者 “%H:%i:%S”
2) extract(year from “2019-12-25 22:47:37”) 從時間提前年/月/日
3) datediff(end_date,start_date) 時間做差,得到日期day
4) timestampdiff( day, end_date,start_date) 時間做差,可選擇返回的時間類型
1、 int(20) 表示字段是int類型,顯示長度是 20
2、 char(20)表示字段是固定長度字符串,長度為 20
3、 varchar(20) 表示字段是可變長度字符串,長度為 20
SQL的執(zhí)行順序:from---where--group by---having---select---order by
第一步:客戶端請求
第二步:連接器(負責跟客戶端建立連接、獲取權(quán)限、維持和管理連接)
第三步:查詢緩存(存在緩存則直接返回,不存在則執(zhí)行后續(xù)操作)
第四步:分析器(對SQL進行詞法分析和語法分析操作)
第五步:優(yōu)化器(主要對執(zhí)行的sql優(yōu)化選擇最優(yōu)的執(zhí)行方案方法)
第六步:執(zhí)行器(執(zhí)行時會先看用戶是否有執(zhí)行權(quán)限,有才去使用這個引擎提供的接口)
第七步:去引擎層獲取數(shù)據(jù)返回(如果開啟查詢緩存則會緩存查詢結(jié)果)
delete和truncate只刪除表的數(shù)據(jù)不刪除表的結(jié)構(gòu)
速度,一般來說: drop> truncate >delete
delete語句是dml,這個操作會放到rollback segement中,事務(wù)提交之后才生效,如果有相應(yīng)的trigger,執(zhí)行的時候?qū)⒈挥|發(fā).
truncate,drop是ddl, 操作立即生效,原數(shù)據(jù)不放到rollback segment中,不能回滾. 操作不觸發(fā)trigger.
● Union:對兩個結(jié)果集進行并集操作,不包括重復(fù)行,同時進行默認規(guī)則的排序;
● Union All:對兩個結(jié)果集進行并集操作,包括重復(fù)行,不進行排序;
● UNION ALL的效率高于 UNION
數(shù)據(jù)庫是一個多用戶使用的共享資源。當多個用戶并發(fā)地存取數(shù)據(jù)時,在數(shù)據(jù)庫中就會產(chǎn)生多個事務(wù)同時存取同一數(shù)據(jù)的情況。若對并發(fā)操作不加控制就可能會讀取和存儲不正確的數(shù)據(jù),破壞數(shù)據(jù)庫的一致性。
加鎖是實現(xiàn)數(shù)據(jù)庫并發(fā)控制的一個非常重要的技術(shù)。當事務(wù)在對某個數(shù)據(jù)對象進行操作前,先向系統(tǒng)發(fā)出請求,對其加鎖。加鎖后事務(wù)就對該數(shù)據(jù)對象有了一定的控制,在該事務(wù)釋放鎖之前,其他的事務(wù)不能對此數(shù)據(jù)對象進行更新操作。
1.從對數(shù)據(jù)操作的類型分類
讀鎖(共享鎖):針對同一份數(shù)據(jù),多個讀操作可以同時進行,不會互相影響
寫鎖(排他鎖):當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖
2.從對數(shù)據(jù)操作的范圍分類
為了盡可能提高數(shù)據(jù)庫的并發(fā)度,理論上每次只鎖定當前操作的數(shù)據(jù),即每次鎖定的數(shù)據(jù)范圍越小就會得到最大的并發(fā)度,但是管理鎖是很耗資源的事情(涉及獲取,檢查,釋放鎖等動作),因此數(shù)據(jù)庫系統(tǒng)需要在高并發(fā)響應(yīng)和系統(tǒng)性能兩方面進行平衡,這樣就產(chǎn)生了“鎖粒度(Lock granularity)”的概念。
表級鎖:開銷小,加鎖快;不會出現(xiàn)死鎖;鎖定粒度大,發(fā)生鎖沖突的概率最高,并發(fā)度最低(MyISAM 和 MEMORY 存儲引擎采用的是表級鎖);適合于以查詢?yōu)橹鳎挥猩倭堪此饕龡l件更新數(shù)據(jù)的應(yīng)用,如Web應(yīng)用;
行級鎖:開銷大,加鎖慢;會出現(xiàn)死鎖;鎖定粒度最小,發(fā)生鎖沖突的概率最低,并發(fā)度也最高(InnoDB 存儲引擎既支持行級鎖也支持表級鎖,但默認情況下是采用行級鎖); 適合于有大量按索引條件并發(fā)更新少量不同數(shù)據(jù),同時又有并發(fā)查詢的應(yīng)用,如一些在線事務(wù)處理(OLTP)系統(tǒng)。
頁面鎖:開銷和加鎖時間界于表鎖和行鎖之間;會出現(xiàn)死鎖;鎖定粒度界于表鎖和行鎖之間,并發(fā)度一般。
悲觀鎖:每次去拿數(shù)據(jù)的時候都認為別人會修改,所以每次在拿數(shù)據(jù)的時候都會上鎖,這樣別人想拿這個數(shù)據(jù)都會block直到它拿到鎖。因此,悲觀鎖需要耗時比較的多,跟樂觀鎖比較,悲觀鎖是有數(shù)據(jù)庫自己實現(xiàn)的,用的時候我們直接調(diào)用數(shù)據(jù)的相關(guān)語句就可以。
樂觀鎖:用數(shù)據(jù)版本記錄機制實現(xiàn),這是樂觀鎖最常用的方式,所謂的數(shù)據(jù)版本,為數(shù)據(jù)增加一個版本號的字段,一般是通過為數(shù)據(jù)表增加一個數(shù)據(jù)類型的version字段實現(xiàn),當讀取數(shù)據(jù)時,將把二十年字段的值一同讀取出來,數(shù)據(jù)每次更新都需要對version值加一,在我們提交更新的時候,判斷數(shù)據(jù)表對應(yīng)記錄的當前版本信息與第一次取出來的version值進行對比,如果數(shù)據(jù)庫的表當前版本號魚取出來的version值相等,則給與更新否則認為過期數(shù)據(jù)不給與更新。
是指二個或者二個以上的進程在執(zhí)行時候,因為爭奪資源造成相互等待的現(xiàn)象,進程一直處于等待中,無法得到釋放,這種狀態(tài)就叫做死鎖。如批量入庫時,存在則更新,不存在則插入,insert into tab(xx,xx) on duplicate key update xx=‘xx’。
1)使用命令 show engine innodb status 查看最近的一次死鎖。
2)InnoDB Lock Monitor 打開鎖監(jiān)控,每 15s 輸出一次日志。使用完畢后建議關(guān)閉,否則會影響數(shù)據(jù)庫性能。
1:通過innodblockwait_timeout來設(shè)置超時時間,一直等待直到超時。其中innodb默認是使用設(shè)置死鎖時間來讓死鎖超時的策略,默認innodblockwait_timeout設(shè)置的時長是50s。
2:發(fā)起死鎖檢測,發(fā)現(xiàn)死鎖之后,主動回滾死鎖中的事務(wù),不需要其他事務(wù)繼續(xù)。
1)為了在單個innodb表上執(zhí)行多個并發(fā)寫入操作時避免死鎖,可以在事務(wù)開始時,通過為預(yù)期要修改行,使用select …for update語句來獲取必要的鎖,即使這些行的更改語句是在之后才執(zhí)行的
2)在事務(wù)中,如果要更新記錄,應(yīng)該直接申請足夠級別的鎖,即排他鎖,而不應(yīng)先申請共享鎖,更新時在申請排他鎖。因為這時候當用戶在申請排他鎖時,其他事務(wù)可能又已經(jīng)獲得了相同記錄的共享鎖,
3)如果事務(wù)需要修改或鎖定多個表,則應(yīng)在每個事務(wù)中以相同的順序使用加鎖語句。在應(yīng)用中,如果不同的程序會并發(fā)獲取多個表,應(yīng)盡量約定以相同的順序來訪問表,這樣可以大大降低產(chǎn)生死鎖的機會。
4)通過 select …lock in share mode獲取行的讀鎖后,如果當前事務(wù)在需要對該記錄進行更新操作,則很有可能造成死鎖;
5)改變事務(wù)隔離級別.
主從復(fù)制就是用來建立一個或多個和主庫一樣的數(shù)據(jù)庫,稱為從庫,然后可以在這兩者之上進行一個讀寫分離,主庫少寫,從庫多讀的操作,這樣就能大大緩解數(shù)據(jù)庫的并發(fā)壓力。
1)做數(shù)據(jù)的熱備份,作為后備數(shù)據(jù)庫,主數(shù)據(jù)庫服務(wù)器故障后,可切換到從數(shù)據(jù)庫繼續(xù)工作,避免數(shù)據(jù)丟失。
2)架構(gòu)的擴展。業(yè)務(wù)量越來越大,I/O訪問頻率過高,單機無法滿足,此時做多庫的存儲,降低磁盤I/O訪問的評率,提高單個機器的I/O性能。
3)讀寫分離,使數(shù)據(jù)庫能支持更大的并發(fā)。在線上環(huán)境中,一般都是讀多寫少,那么我們可以在主庫中實現(xiàn)寫操作,然后在從庫實現(xiàn)讀操作,這樣就能很好的分擔壓力.
1. 首先從庫創(chuàng)建I/O線程去請求主庫 的binlog
2. 然后主庫創(chuàng)建一個binlog dump線程將數(shù)據(jù)同步到binlog文件中.
3. 然后從庫I/O線程將binlog文件數(shù)據(jù)同步到自身的redo log文件中.
4. 然后從庫創(chuàng)建一個sql線程將redo log文件里的數(shù)據(jù)同步到數(shù)據(jù)庫里.
1.因為從庫復(fù)制binlog文件的這個IO線程是單線程,所以如果出現(xiàn)網(wǎng)絡(luò)阻塞等情況,那么主庫的寫操作肯定要比復(fù)制數(shù)據(jù)要快,這個時候就會導(dǎo)致從庫復(fù)制延遲,數(shù)據(jù)不一致.
2.在從庫用sql線程將redo log文件里的數(shù)據(jù)復(fù)制到數(shù)據(jù)庫里的時候,可能會被對該表的操作阻塞,比如有另外的線程進行鎖表的操作,那么該導(dǎo)入數(shù)據(jù)的sql線程就會被阻塞.此時也會導(dǎo)致復(fù)制延遲.
3.如果中間過程出現(xiàn)了宕機,可能會產(chǎn)生數(shù)據(jù)丟失的問題.
1.解決數(shù)據(jù)丟失,很簡單,可以采用半同步復(fù)制策略.即在進行同步復(fù)制的時候,主庫要求必須要有一個從庫進行回應(yīng)后才能確定復(fù)制成功,確保數(shù)據(jù)至少復(fù)制到了一臺從機了.
2.解決復(fù)制延遲問題可以采用并行復(fù)制,這是自5.6后提出的,到5.7后得以升級傳播,此后多個數(shù)據(jù)庫版本出現(xiàn)就有多個版本的并行復(fù)制,這里截取網(wǎng)上一種通用說法,跟面試官說說就可以了,畢竟我們是剛出去工作的小白:
MySQL為了解決這個問題,將sql_thread演化了多個worker的形式,在slave端并行應(yīng)用relay log中的事務(wù),從而提高relay log的應(yīng)用速度,減少復(fù)制延遲。
水平分庫
概念:以字段為依據(jù),按照一定策略(hash、range等),將一個庫中的數(shù)據(jù)拆分到多個庫中。
結(jié)果:每個庫的結(jié)構(gòu)都一樣,擁有相同的表數(shù)量;每個庫的數(shù)據(jù)都不一樣,沒有交集,所有庫的并集是全量數(shù)據(jù);
垂直分庫
概念:以表為依據(jù),按照業(yè)務(wù)歸屬不同,將不同的表拆分到不同的庫中。拆分對象是表
結(jié)果:每個庫的結(jié)構(gòu)都不一樣,比如abcd四張表,ab表放x庫,cd表放y庫;每個庫的數(shù)據(jù)也不一樣,沒有交集,所有庫的并集是全量數(shù)據(jù);
水平分表
概念:以字段為依據(jù),按照一定策略(hash、range等),將一個表中的數(shù)據(jù)拆分到多個表中。
結(jié)果:每個表的結(jié)構(gòu)都一樣;每個表的數(shù)據(jù)都不一樣,沒有交集;所有表的并集是全量數(shù)據(jù);
垂直分表
概念:以字段為依據(jù),按照字段的活躍性,將熱點字段放在一張表,非熱點字段放一張表。
結(jié)果:每個表的結(jié)構(gòu)都不一樣,idabcd五個字段,idab字段放x表,idcd字段放y表;都存有主鍵,通過主鍵來關(guān)聯(lián)
很簡單,只需要在主鍵后面添加AUTO_INCREMENT關(guān)鍵字就行了
CREATE TABLE `user`(
?? ?id INT PRIMARY KEY AUTO_INCREMENT,
?? ?username VARCHAR(10),
?? ?`password` VARCHAR(20)
);
剛才,我們在user表中已經(jīng)把主鍵id設(shè)置為自增的了,但是又在表中插入了一條設(shè)置了id值的數(shù)據(jù)
insert into `user` values(1, "張三", "zs666")
那么MySQL會直接忽略掉我們自己設(shè)置的id,繼續(xù)通過自增來設(shè)置插入數(shù)據(jù)的id
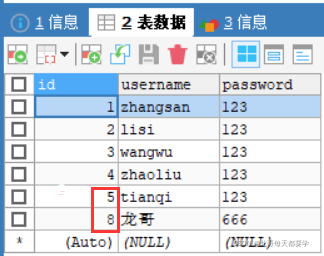
例如id從5直接跳到了8,這是因為我們之前在嘗試進行插入操作時,雖然事務(wù)沒有提交,但是id已經(jīng)自增了
主鍵建議是自增的好。因為InnoDB中的主鍵是聚簇索引,如果主鍵是自增的話,每次插入新的記錄就會順序添加到當前索引節(jié)點的后續(xù)位置,當一頁寫滿就會自動開辟新的頁。如果不是自增主鍵,可能就會在中間插入,引發(fā)頁的分裂導(dǎo)致產(chǎn)生很多表空間的碎片。可以理解為當主鍵是UUID的時候,插入表記錄的時間會更長,占用空間也會更大。
1.任何有業(yè)務(wù)含義的列都有改變的可能性,主鍵一旦帶上了業(yè)務(wù)含義,那么主鍵就有可能發(fā)生變更。而主鍵一旦發(fā)生變更,該記錄數(shù)據(jù)在磁盤上的存儲位置就會發(fā)生改變,甚至有可能會引發(fā)頁分裂導(dǎo)致產(chǎn)生空間碎片。
2.帶有業(yè)務(wù)含義的主鍵就不一定是順序自增的了,這樣就會導(dǎo)致數(shù)據(jù)的插入順序不到有序的,也不能保證后面插入數(shù)據(jù)的主鍵一定比前面的數(shù)據(jù)大。如果出現(xiàn)了后面插入數(shù)據(jù)的主鍵比前面的小的情況,就有可能引發(fā)頁分裂導(dǎo)致產(chǎn)生空間碎片。
表示枚舉的字段一般選用tinyint類型。不選用enum類型主要有兩個原因:
1.enum類型的order by的操作效率低,需要額外的操作。
2.如果枚舉值是數(shù)值類型的,會很容易出現(xiàn)語法陷阱,枚舉的下標和數(shù)值很容易會被弄混淆。
如果貨幣單位是分,可以是int類型;如果堅持用元,則要用decimal類型。
但是是不能用float和double類型的,因為這兩個類型是以二進制存儲的,會有一定的誤差。比如float類型如果你insert一個1234567.23,查詢出來的結(jié)果可能是1234567.25。
時間字段的話需要結(jié)合項目背景,varchar、timestamp、datetime或bigint類型都可以。
1.varchar類型。如果用varchar類型來存時間,優(yōu)點在于顯示直觀,存取都方便。但是缺點也是挺多的,比如插入的數(shù)據(jù)沒有校驗,某一天你可能會發(fā)現(xiàn)數(shù)據(jù)庫中存了一個2019-06-31的數(shù)據(jù)。其次,做時間比較運算時需要用str_to_date()等函數(shù)將其轉(zhuǎn)化為時間類型,除非建立基于函數(shù)的索引,否則這么寫是無法命中索引的,數(shù)據(jù)量一大,查詢效率就會很低。
2.timestamp類型。這個類型是四個字節(jié)的整數(shù),它能表示的時間范圍為1970-01-01 08:00:01到2038-01-19 11:14:07,而2038年以后的時間,是無法用timestamp類型存儲的。但是它有一個優(yōu)勢是它帶有時區(qū)信息的,一旦系統(tǒng)中的時區(qū)發(fā)生改變,項目中的該字段的值也會自己發(fā)生改變。
3.datetime類型。datetime類型的儲存占用8個字節(jié),存儲的時間范圍為1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。顯然,存儲時間范圍更大,但是它存儲的是時間絕對值,不帶有時區(qū)信息。如果改變了數(shù)據(jù)庫的時區(qū),該項的值不會自己發(fā)生變更。
4.bigint類型。這個類型也是8個字節(jié),自己維護一個時間戳,表示范圍比timestamp類型大多了。缺點就是要自己維護,不大方便。
在實際應(yīng)用中,一般都是用HDFS來存儲文件的,在MySQL中只會存文件的存放路徑。但是實際上MySQL是有提供兩個字段類型被涉及用來存放大容量文件的,一個是text類型,一個是blob類型。然而在生產(chǎn)中基本不會使用這兩個類型,主要原因如下:
1.MySQL內(nèi)存臨時表不支持text和blob這樣的大數(shù)據(jù)類型。如果查詢中包含這樣的數(shù)據(jù),那么在排序等操作的時候就不能夠使用內(nèi)存臨時表,只能使用磁盤臨時表,會導(dǎo)致查詢效率低下。
2.這兩種類型會造成binlog的內(nèi)容太多。因為數(shù)據(jù)的內(nèi)容比較大,也就會造成binlog的內(nèi)容比較多。我們知道,主從同步是通過binlog來進行的,如果binlog過大,就會導(dǎo)致主從同步的效率問題。
1.索引的性能不好。MySQL難以優(yōu)化引用可空列查詢,它會使得索引、索引統(tǒng)計和值更加復(fù)雜。可空列需要更多的存儲空間,還需要MySQL內(nèi)部進行特殊處理。可空列被索引后,每條記錄都需要一個額外的字節(jié)。
2.查詢可能會出現(xiàn)一些不可預(yù)料的結(jié)果。比如說使用count()聚合函數(shù)去統(tǒng)計一個可為空的字段,那么最后統(tǒng)計出來的記錄數(shù)可能會和實際的記錄數(shù)不同。
1)字段最多存放 50 個字符
2)如 varchar(50) 和 varchar(200) 存儲 "jay" 字符串所占空間是一樣的,后者在排序時會消耗更多內(nèi)存
在優(yōu)化MySQL時,通常需要對數(shù)據(jù)庫進行分析,常見的分析手段有慢查詢?nèi)罩荆珽XPLAIN 分析查詢,profiling分析以及show命令查詢系統(tǒng)狀態(tài)及系統(tǒng)變量,通過定位分析性能的瓶頸,才能更好的優(yōu)化數(shù)據(jù)庫系統(tǒng)的性能。
1 慢查詢?nèi)罩?br />
MySQL 的慢查詢?nèi)罩居脕碛涗浽?MySQL 中響應(yīng)時間超過閾值的語句,具體指運行時間超過long_query_time值的 SQL,則會被記錄到慢查詢?nèi)罩局?br />
● long_query_time的默認值為10,意思是運行10秒以上的語句。
● 默認情況下,MySQL數(shù)據(jù)庫沒有開啟慢查詢?nèi)罩荆枰謩釉O(shè)置參數(shù)開啟
------------------------------------------------
修改配置文件my.cnf或my.ini,在[mysqld]一行下面加入兩個配置參數(shù)
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/hostname-slow.log
long_query_time = 3
在生產(chǎn)環(huán)境中,如果手工分析日志,查找、分析SQL,還是比較費勁的,所以MySQL提供了日志分析工具mysqldumpslow。
2 Explain(執(zhí)行計劃)
使用 Explain 關(guān)鍵字可以模擬優(yōu)化器執(zhí)行SQL查詢語句,從而知道 MySQL 是如何處理你的 SQL 語句的。分析你的查詢語句或是表結(jié)構(gòu)的性能瓶頸
3 Show Profile 分析查詢
Show Profile 是 MySQL 提供可以用來分析當前會話中語句執(zhí)行的資源消耗情況。可以用于SQL的調(diào)優(yōu)的測量。默認情況下,參數(shù)處于關(guān)閉狀態(tài),并保存最近15次的運行結(jié)果 .
1、先運行看看是否真的很慢,注意設(shè)置SQL_NO_CACHE
2、where條件單表查,鎖定最小返回記錄表。這句話的意思是把查詢語句的where都應(yīng)用到表中返回的記錄數(shù)最小的表開始查起,單表每個字段分別查詢,看哪個字段的區(qū)分度最高
3、explain查看執(zhí)行計劃,是否與1預(yù)期一致(從鎖定記錄較少的表開始查詢)
4、order by limit 形式的sql語句讓排序的表優(yōu)先查
5、了解業(yè)務(wù)方使用場景
6、加索引時參照建索引的幾大原則
7、觀察結(jié)果,不符合預(yù)期繼續(xù)從0分析
① 盡可能的使用復(fù)合索引而不是索引的組合;
②創(chuàng)建索引盡量讓輔助索引進行索引覆蓋 而不是回表;
③在可以使用主鍵id的表中,盡量使用自增主鍵id,這樣可以避免頁分裂;
④查詢的時候盡量不要使用select * ,這樣可以避免大量的回表;
⑤盡量少使用子查詢,能使用外連接就使用外連接,這樣可以避免產(chǎn)生笛卡爾集;
⑥能使用短索引就是用短索引,這樣可以在非葉子節(jié)點存儲更多的索引列降低樹的層高,并且減少空間的開銷;
(1)Where子句中:where表之間的連接必須寫在其他Where條件之前,那些可以過濾掉最大數(shù)量記錄的條件必須寫在Where子句的末尾.HAVING最后。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3)避免在索引列上使用計算
(4)避免在索引列上使用IS NULL和IS NOT NULL
(5)對查詢進行優(yōu)化,應(yīng)盡量避免全表掃描,首先應(yīng)考慮在 where 及 order by 涉及的列上建立索引。
(6)應(yīng)盡量避免在 where 子句中對字段進行 null 值判斷,否則將導(dǎo)致引擎放棄使用索引而進行全表掃描
(7)應(yīng)盡量避免在 where 子句中對字段進行表達式操作,這將導(dǎo)致引擎放棄使用索引而進行全表掃描
首先對于索引的維護來說是需要成本的,我們對數(shù)據(jù)的增/刪/修改,刪除,都會產(chǎn)生額外的對索引文件的操作,這些操作需要消耗額外的IO,會降低增/改/刪的執(zhí)行效率。所以,在我們刪除數(shù)據(jù)庫百萬級別數(shù)據(jù)的時候,刪除數(shù)據(jù)的速度和創(chuàng)建的索引數(shù)量是成正比的,如果直接刪除很可能會產(chǎn)生中斷情況,所以我們想要刪除百萬數(shù)據(jù)的時候可以做如下操作:
1. 先刪除索引(此時大概耗時三分多鐘)
2. 然后刪除其中無用數(shù)據(jù)(此過程需要不到兩分鐘)
3. 刪除完成后重新創(chuàng)建索引(此時數(shù)據(jù)較少了創(chuàng)建索引也非常快,約十分鐘左右)
簡單來說在高并發(fā)情況下當前讀是獲取最新的記錄并且其他事務(wù)不能修改這個記錄、快照讀獲取的有可能是老的數(shù)據(jù)。當前讀是加了鎖的,并且加的是悲觀鎖。而快照讀是沒加鎖的。
MVCC,全稱Multi-Version Concurrency Control,即多版本并發(fā)控制,是一種高并發(fā)版本控制器,一般用于數(shù)據(jù)庫中對數(shù)據(jù)的并發(fā)訪問。Mysql中的innoDB中就是使用這種方法來提高讀寫事務(wù)的并發(fā)性能。因為MVCC是一種不采用鎖來控制事務(wù)的方式,是一種非堵塞、同時還可以解決臟讀,不可重復(fù)讀,幻讀等事務(wù)隔離問題,但不能解決更新丟失問題。
總之:就是MVCC是通過保存數(shù)據(jù)的歷史版本,根據(jù)比較版本號來處理數(shù)據(jù)是否顯示,從而達到讀取數(shù)據(jù)的時候不需要加鎖就可以保證事務(wù)隔離性的效果。
MVCC的實現(xiàn)原理是依靠記錄中的3個隱含字段、undo log日志(回滾日志 )、Read View來實現(xiàn)的。
1:隱含字段:
DB_TRX_ID:記錄操作該數(shù)據(jù)事務(wù)的事務(wù)id;
DB_ROLL_PTR:指向上一個版本數(shù)據(jù)在undo log里的位置指針
DB_ROW_ID:隱藏ID,當創(chuàng)建表沒有合適的索引作為聚集索引時,會用該隱藏ID創(chuàng)建聚集索引
2:undo log日志:
insert undo log:在進行插入操作事務(wù)時產(chǎn)生、在事務(wù)回滾時需要、在提交事務(wù)后可以被立即丟掉
update undo log:進行update、delete時產(chǎn)生的undo log、不僅在回滾事務(wù)時需要、在快照讀時也需要。所以不能隨便刪除,只有在快照讀或事務(wù)回滾不涉及該日志時,對應(yīng)的日志才會被purge線程統(tǒng)一清除(purge類似jvm中的gc垃圾回收器)
3:Read View(讀視圖)
Read View讀視圖就是用來記錄發(fā)生快照讀那一刻所有的記錄,當你下次就算有執(zhí)行新的事務(wù)記錄改變了,read view沒變,讀出來的數(shù)據(jù)依然是不變的。
而隔離級別中的RR(可重復(fù)讀)、和RC(提交讀)不同就是差在快照讀時。前者創(chuàng)建一個快照和Read View,并且下次快照讀時使用的還是同一個Read View,所以其他事務(wù)修改數(shù)據(jù)對他是不可見的、解決了不可重復(fù)讀問題。后者則是每次快照讀時都會產(chǎn)生新的快照和Read View所以就會產(chǎn)生不可重復(fù)讀問題。
MySQL 數(shù)據(jù)庫中有六種觸發(fā)器:
● Before Insert、After Insert
● Before Update、After Update
● Before Delete、After Delete
開啟Mysql的查詢緩存,當執(zhí)行完全相同的SQL語句的時候,服務(wù)器就會直接從緩存中讀取結(jié)果,當數(shù)據(jù)被修改,之前的緩存會失效,修改比較頻繁的表不適合做查詢緩存。
1. 查看當前的MySQL數(shù)據(jù)庫是否支持查詢緩存:
SHOW VARIABLES LIKE 'have_query_cache';
2. 查看當前MySQL是否開啟了查詢緩存 :
SHOW VARIABLES LIKE 'query_cache_type';
3. 查看查詢緩存的占用大小 :
SHOW VARIABLES LIKE 'query_cache_size';
4. 查看查詢緩存的狀態(tài)變量:
SHOW STATUS LIKE 'Qcache%';
1) SQL 語句不一致的情況, 要想命中查詢緩存,查詢的SQL語句必須完全一致。
select count(*) from tb_item; SQL2 : Select count(*) from tb_item;
2) 當查詢語句中有一些不確定的時,則不會緩存。如 : now() , current_date() , curdate() , curtime() , rand() ,uuid() , user() , database() 。
select * from tb_item where updatetime < now() limit 1;?
select user();?
select database();
3) 不使用任何表查詢語句。
select 'A';
4) 查詢 mysql, information_schema或 performance_schema 數(shù)據(jù)庫中的表時,不會走查詢緩存。
select * from information_schema.engines;
5) 在存儲的函數(shù),觸發(fā)器或事件的主體內(nèi)執(zhí)行的查詢。
6) 如果表更改,則使用該表的所有高速緩存查詢都將變?yōu)闊o效并從高速緩存中刪除。這包括使用 MERGE 映射到已更改表的表的查詢。一個表可以被許多類型的語句,如被改變 INSERT, UPDATE, DELETE,TRUNCATE TABLE, ALTER TABLE, DROP TABLE,或 DROP DATABASE 。
● 盡量用小范圍的數(shù)據(jù)類型:一般情況下,應(yīng)該盡量使用可以正確存儲數(shù)據(jù)的最小范圍數(shù)據(jù)類型。
● 盡量用整型:簡單的數(shù)據(jù)類型通常需要更少的CPU周期。例如,整數(shù)比字符操作代價更低,因為字符集和校對規(guī)則(排序規(guī)則)使字符比較比整型比較復(fù)雜。
● 盡量避免NULL:通常情況下最好指定列為NOT NULL 。
最好是按照以下順序優(yōu)化:
1.SQL語句及索引的優(yōu)化
2. 數(shù)據(jù)庫表結(jié)構(gòu)的優(yōu)化
3.系統(tǒng)配置的優(yōu)化
4.硬件的優(yōu)化

官方微信

官方抖音










 京公網(wǎng)安備 11030102010736號
京公網(wǎng)安備 11030102010736號